JPA saveAll 이 단건으로 나가는 이유
목차
1. 문제 발생 #
이전에 참여했던 랩실 프로젝트의 요구사항 중에 다음 기능이 있었다.
- 최대 10만 라인 정도의 csv 파일을 읽어와 학습 용 데이터로 가공 후 데이터 베이스에 저장하기
개발 스택은 Mariadb + Spring boot 3 에 JPA를 사용 중 이였다.
그래서 먼저 csv 파일을 읽어와 필요한 태그 데이터를 추출하고, 데이터를 엔티티로 생성하여 처리하였다.
- 초기에는 JpaRepository 의 save() 메소드를 사용하여 단건처리를 시도하였다.
-> 당연히 10만개의 엔티티가 생성되고, 이 엔티티들이 전부 영속성 컨텍스트에 들어가버리니 OOM이 발생했다.
- 두번째 부터는 데이터를 한번에 올리지 않고, 일정 수량 만큼 데이터를 처리하여, JpaRepository 의 saveAll() 메소드로 처리를 시도하였다.
-> OOM은 해결되었으나, 너무 긴 처리 시간이 발생하였는데, 로그 확인 결과 의도한대로 bulk insert 처리되지 않고, 개별 insert로 처리가 되고 있었다.
2. 원인 분석 #
이는 현재 사용중인 GenerationType.IDENTITY 의 구동 방식 때문에 의도한대로 묶어서 처리 되지 않고 개별 처리가 발생하는 문제였다.
a. 하이버네이트의 엔티티 저장 과정 #
하이버네이트에서는 영속성 컨텍스트에서 엔티티를 관리할 때, @Id 어노테이션으로 명시한 id 필드를 키로 엔티티를 관리한다.
@Entity(name="DATA")
class Data(
@Id
var id: Long,
var text: String,
var type: Int
)
val data = Data(id=1L,text="이것은 테스트 데이터입니다.",type="1")
위 코드 처럼 엔티티를 생성하게 되면, 아직 영속성 컨텍스트에서 관리되기 이전의 비영속 상태의 엔티티를 생성할 수 있다.
이때 엔티티 매니저의 persist 메소드를 호출하게 되면, 해당 엔티티를 영속 상태로 만들 수 있다.
// 비영속 상태
val data = Data(text="이것은 테스트 데이터입니다.",type="1")
entityManager.persist(data) // 이제는 영속 상태
실제 구현에서 많이 쓰이는 방식은 save 메소드 호출일텐데, SimpleJpaRepository.save() 구현을 살펴보면 다음과 같다.
@Override
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, ENTITY_MUST_NOT_BE_NULL);
if (entityInformation.isNew(entity)) {
entityManager.persist(entity);
return entity;
} else {
return entityManager.merge(entity);
}
}
새롭게 저장할 엔티티 임이 확인되면, entityManager.persist() 를 호출해 영속 상태로 만든다는 것을 알 수 있다.
다만 이렇게 영속 상태가 되었다고 해서, 즉시 저장되는 것은 아니고, 쓰기 지연을 통해 모아두었다가, 트랜잭션이 끝나고 flush가 호출되면, 그때 한번에 insert 처리된다.
GenerationType 전략별 단건 처리 방식 #
하지만 실제 개발시에는 이렇게 수동으로 PK를 관리하는 일은 거의 없을 것이다. 대부분은 엔티티의 PK 필드에 @Id와 @GeneratedValue 애노테이션을 달고 DB에 id 생성을 위임하게 될 것이다.
@Entity(name = "data")
class Data(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null
......
)
이때 위에서 언급했듯이, 하이버네이트는 id로 영속 상태의 엔티티를 관리하기 때문에 id가 필요하다. 하지만 이런 경우 id가 null로 존재하지 않는다. 따라서 기존 쓰기 지연 방식이 아닌 다른 방식으로 동작하게 되는데, @GeneratedValue 의 전략에 따라 처리하게 된다. 해당 글에서는 IDENTITY,SEQUENCE에 대해 살펴보겠다.
GenerationType.IDENTITY #
이 전략은 기본 키 생성을 데이터베이스의 AUTO_INCREMENT에 완전히 위임하게 된다. 즉 데이터베이스에 실제로 데이터를 넣기 전까지 pk를 알 수 없게 된다.
따라서 이 경우 다음과 같이 동작한다.
- 엔티티가 영속상태가 된다.
- 영속성 컨텍스트에 넣기 위해 id를 확인하지만, 없다.
- 따라서 하이버네이트는 영속 상태로 만들기 위해 쓰기 지연 방식이 아닌, 즉시 insert를 수행한다.
- jdbc의
Statement.getGeneratedKeys()를 사용하여 insert 된 엔티티의 pk를 가져온다. - 해당 pk 값을 엔티티에 넣고, 영속성 컨텍스트에 해당 엔티티를 등록한다.
결론적으로 핵심은 이것이다. 쓰기 지연 방식이 아닌 즉시 insert 된다는 점을 확인해야한다.
주로 Mariadb나 Mysql 데이터베이스에서 해당 전략을 사용하게 된다.
GenerationType.SEQUENCE #
이 전략은 데이터베이스가 제공하는 독립적인 SEQUENCE 객체를 사용하여 PK를 생성한다. IDENTITY와 가장 큰 차이점은 데이터를 INSERT 하기 전에 PK 값만 미리 빼올 수 있다 라는 점이다.
따라서 이 경우 다음과 같이 동작한다.
- 엔티티가 영속상태가 된다.
- 영속성 컨텍스트에 넣기 위해 id를 확인하지만, 없다.
SELECT NEXTVAL을 호출하여 생성될 pk 값을 미리 받아온다.- 해당 pk 값을 엔티티에 넣고, 영속성 컨텍스트에 해당 엔티티를 등록한다.
- 해당 엔티티는 쓰기 지연 저장소에 쌓인다.
- flush 호출시 실제로 insert 쿼리가 날라간다.
따라서 IDENTITY 전략과 다른점은 실제로 데이터를 넣지 않고서도 pk를 확보할 수 있다는 점이다.
오라클, PostgreSQL 등에서 주로 사용한다.
아래에서 문제의 본질인 Bulk Insert 처리 과정을 살펴보겠다.
b. 하이버네이트의 엔티티 Bulk Insert 처리 과정 #
자 이때 Bulk Insert 로직을 살펴봐야한다. saveAll 메소드를 살펴보면 다음과 같이 작성되어 있다.
@Override
@Transactional
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, ENTITIES_MUST_NOT_BE_NULL);
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
전체 엔티티를 받아, for로 save 를 호출 중인 모습이다. 즉 saveAll 이라고 해서 우리가 for로 save를 돌리는 것과 별반 차이가 없다는 것이다.
GenerationType 전략별 Bulk Insert 처리 방식 #
위에서 살펴본 결과대로면 사실 saveAll이 저렇게 동작하기에 saveAll()을 호출하더라도 단건처리가 된다고 생각할 수 있다. 하지만 전략별로 처리되는 방식을 살펴보면 차이가 있음을 알 수 있다.
GenerationType.SEQUENCE 전략의 Bulk Insert #
시퀀스 전략의 핵심은 @SequenceGenerator 의allocationSize 필드이다. for을 돌때 매번 SELECT NEXTVAL 을 호출하는 것이 아닌, 실제로는 해당 수치만큼 미리 땡겨오게 된다. 따라서 다음과 같이 동작하게 된다.
saveAll()의 첫 번째 for 문이 돌 때,allocationSize만큼SELECT NEXTVAL을 날린다.- 해당 값을 메모리에 저장하고, for문이 돌때 해당 값을 사용한다.
- 메모리의 모든 값이 떨어지면, 다시 호출하여 값을 받아오고, 이를 반복한다.
즉 시퀀스 전략은 직접 insert 하지 않고도 미리 pk를 알 수 있기에 아에 미리 땡겨오는 방식을 사용한다. 이 방식 때문에 시퀀스 전략을 사용하여 bulk insert를 수행하면, 한번에 묶어서 수행한다.
GenerationType.IDENTITY 전략의 Bulk Insert #
하지면 IDENTITY 은 다르다. 미리 pk를 알 수 없기에 결국 아래와 같이 동작한다.
엔티티 리스트가 들어온다.
엔티티 하나를 리스트에서 가져온다.
- 영속성 컨텍스트에 넣기 위해 id를 확인하지만, 없다.
- 따라서 하이버네이트는 영속 상태로 만들기 위해 쓰기 지연 방식이 아닌, 즉시 insert를 수행한다.
- jdbc의
Statement.getGeneratedKeys()를 사용하여 insert 된 엔티티의 pk를 가져온다. - 해당 pk 값을 엔티티에 넣고, 영속성 컨텍스트에 해당 엔티티를 등록한다.
위 과정을 반복한다.
다시 말해 쓰기 지연 저장소를 못쓰기에 단건 쿼리가 발생한다는 점이다.
3. 문제 원인 #
결국 문제 원인은 단순하다. GenerationType.IDENTITY 를 사용 중 이라면, 위에서 살펴본 하이버네이트의 성격 때문에 saveAll 메소드로 bulk insert 를 처리할려고 해도 결국 단건으로 처리된다는 점이다. 따라서 다음 해결 방안들을 선택해볼 수 있다.
4. 해결 방안들 #
- Connection String 및 JPA 배치 사이즈 적용 확인
기본적으로 bulk insert를 수행하려고 해도, connection string에 rewriteBatchedStatements=true 을 넣어주어야 묶어서 나가며,
properties 에 반드시 JPA 배치 사이즈를 적용해주어야 한다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 1000
order_inserts: true
order_updates: true
- 다른 GenerationType 사용하기
정말 놀랍게도 mariadb 10.3 부터는 SEQUENCE 를 지원한다. 그렇기에 테이블 설계 시, AUTO_INCREMENT가 아닌, SEQUENCE 를 선택한다면, 정상적으로 bulkinsert 됨을 알 수 있다.
- JDBC로 처리하기
필자가 선택한 방식이다. 문제 상황을 본질적으로 생각해보면, jpa의 영속성 컨텍스트 자체가 필요 없는 상황이다. 불필요한 기능 때문에 이러한 오버헤드를 감수하는 것이 잘못된 전략이라고 생각했기에, 기존 엔티티는 dto, 즉 그저 데이터를 담는 요소로만 사용하고, jdbc의 JdbcTemplate.batchUpdate() 메소드를 사용하였다.
벤치마크 #
10만건 의 csv 파일을 읽어와 1000 batch size로 잘라 bulk insert 처리를 수행해보았다.
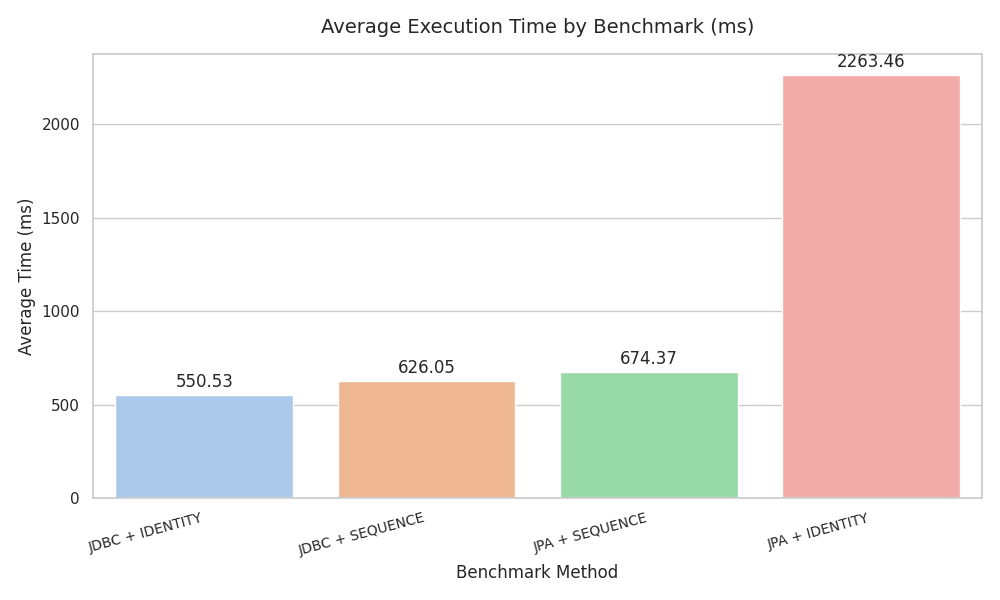
당연히 JDBC + IDENTITY 조합이 가장 빠른 성능을 보여주었다. 다만 의외로 JPA + SEQUENCE 가 상당히 괜찮은 성능을 보여주었는데, 정말 JPA 영속성 컨텍스트가 필요하고, SEQUENCE로 key 생성 전략을 적용할 수 있을 때는 생각해볼만한 선택지인 것 같다.
5. 결론 #
JPA의 Bulk Insert시 IDENTITY ID 전략을 사용중이라면, 단건 처리된다. 따라서 이경우 SEQUENCE를 고려해보거나, JPA의 영속성 컨텍스트가 필요 없는 이런 케이스의 경우 JDBC를 사용하여 bulk insert 하는 것이 좋다.